R2DBC Pagination / Stream 성능 / 비밀번호 암호화
가을이 오고 있다.
올해도 어느덧 다 지나가고 있는 것 같다.
더 뿌듯한, 자랑스러운 올해를 만들기 위해 노력해야지.
그럼, 내 생일이기도 한 오늘의 뉴스도 시작.
Spring data r2dbc pagination #
(Link) Spring data r2dbc pagination example
최근 r2dbc, Spring data r2dbc를 사용하고 있다.
JPA와 여러가지 차이가 있지만, 그래도 Spring data 측에서 Spring data jpa처럼 유사하게 제공을 하고 있어 사용하는 측면에서는 비슷하게 다룰 수 있다. (JPA와 차이에 대한 내용은 제 블로그 글 참조)
근데 하나 차이가 있다면, Page 인터페이스이다.
Spring data jpa를 사용한다면 Pageable 사용 시 다음과 같이 사용할 수 있다.
public interface SomeRepository extends JpaRepository<Some, Long> {
Page<Some> findAllBy(Pageable pageable);
}
하지만 R2dbc의 경우, 이렇게 사용할 수 없다. Mono, Flux로 타입이 제한되기 때문이다.
즉, 2개 이상의 데이터의 경우 Page, List가 아닌 Flux로 반환된다.
public interface SomeRepository extends R2dbcRepository<Some, Long> {
Flux<Some> findAllBy(Pageable pageable);
Mono<Page<Some>> findAllBy(Pageable pageable); // 불가능
Flux<Page<Some>> findAllBy(Pageable pageable); // 불가능
}
위 R2dbc 예시에서 Parameter로 전달되는 Pageable 인터페이스(PageRequest 구현체)를 통해 Pagination은 구현은 잘 될 수 있다.
근데 Page 타입을 사용한다는 것은 Page 정보(Page size, Page number 등)가 필요해 사용하는 경우가 많은데, 위에서는 그 정보를 받을 수 없다.
그럼, 이 정보를 어떻게 얻을 수 있을까?
그 해답은 count 쿼리를 수동으로 구성하고, 이를 사용해 PageImpl 인스턴스를 직접 만들어 반환하는 방법이다.
@Service
public class ProductService {
@Autowired
private ProductRepository productRepository;
public Mono<Page<Product>> getProducts(PageRequest pageRequest){
return productRepository.findAllBy(pageRequest))
.collectList()
.zipWith(this.productRepository.count())
.map(t -> new PageImpl<>(t.getT1(), pageRequest, t.getT2()));
}
}
- 이렇게 구성하면,
Mono<Page<Product>>를 반환할 수 있게 되어 Page 정보들을 반환할 수 있게 된다.
참고로, 위 코드는 Transactional annotation이 붙지 않았다. 만약 붙이게 되면 오류가 발생할 수 있다.
Transactional annotation이 붙으면 내부에서 하나의 Database connection을 사용하게 되고 zipWith는 병렬로 수행되기 때문에, findAllBy 쿼리와 count 쿼리가 하나의 Connection에서 동시에 실행될 수 있기 때문이다.
그러므로 Transactional 문제를 해결하기 위해서는 zipWith가 아닌 flatMap 같은 순차적으로 연산이 동작할 수 있게 구성하거나, 새로운 메서드로 만들어 Transacitonal propagation(전파) 속성을 이용해 새로운 Transaction 내에서 동작(REQUIRES_NEW)하도록 구성해야 한다. (새로운 메서드로 구성 시에는 self invocation 문제를 조심하자)
Java Stream API는 왜 for-loop보다 느릴까? #
(Link) The Performance Model of Streams in Java 8
(Link) 번역 및 해설 - Java Stream API는 왜 for-loop보다 느릴까?
Java로 개발할 때, 거의 대부분 For loop 대신 Stream을 활용해 구성한다.
선언식과 또 여러 함수형 메서드를 연결 지을 수 있다는 점, 코드가 간결해지고 사이드 이펙트를 방지할 수 있다는 점 등 장점이 엄청 많기 때문이다.
근데 저 글에서 나와있듯 알고리즘 문제를 푸는 것에서는 손이 안가게 된다.
나는 2가지 이유였다.
- 알고리즘 문제의 경우, loop 내에서 외부 값을 변경해야할 일이 많다. Stream Pipeline 상에서 값을 계속 주고받기에는 너무 복잡해진다.
- for loop보다 느리게 동작한다. 결과 성공시간만 봐도 그렇다.
2번째 이유에 대해 항상 궁금했었는데 찾아보다가 위 글을 보게 되었고, 엄청 재미있게 읽었다.
처음에 primitive type int 배열 중 최대 값을 구하는 작업을 비교하는데 for loop가 Stream보다 15배 정도 빠르게 동작한다.
- JIT compiler가 for loop에 대해 optimization이 잘되어 있기 때문 (즉, Compilation tier가 높게 잡혀 기계어로 동작하게 됨을 의미한다).
Wrapped class인 Integer와 ArrayList를 사용하면 어떨까? for loop 성능이 엄청나게 느려진다. 그래도 Stream보다는 빠르다. 하지만 Stream과 차이가 1.27배 정도 밖에 나지 않는다.
Integer class를 사용하면서 ArrayList를 활용하게 되었는데, 이를 순회하는 것은 매우 비싸기 때문이라고 한다. 어찌되었든 Wrapped class를 다루게되고, 이는 Stack이 아닌 Heap에 저장되게 된다.
즉, Primitive type은 Stack에서 바로 접근해서 실제 내용을 가져올 수 있는 반면 Wrapped class는 Heap까지 가서 데이터를 찾아와야 하므로 성능에 영향을 주었다고 이야기한다.
Loop 중 아주 비싼 연산(시간복잡도가 큰 작업)을 하게되면 어떻게 될까? 성능에 더 차이가 없게 된다.
그 이유에 대해서는 자세히 나오지는 않는데, JIT Compiler의 최적화와 for loop을 구성하는데 부가적인 연산들이 들어가기 때문이라고 추측했다.
결론적으로 '순회비용'과 '연산비용'이 큰 상황에서는 Stream과 For loop의 성능차이가 크지 않고, 만약 '순회비용'과 '연산비용'이 적다면 For loop 성능이 더 우수하다.
- (사견) 성능이 중요한 애플리케이션이라면 이런 것들을 고려해야할 것이지만, 그런 것이 아니라면 사실 유지보수성을 위해 Stream을 활용하는 편이 좋지 않을까 싶다.
병렬 스트림과 비교하는 부분도 있는데, 포크 조인 풀 및 어떤 상황에서 활용하는지 등에 대한 내용이 있는데 참고하면 좋을 것 같다.
비밀번호 암호화 - Hash, Salt #
(Link) Adding Salt to Hashing: A Better Way to Store Passwords
보안이라고는 학부 수준에서 학습했던 것 밖에 없어 계속 까먹게 된다.
최근 Salt에 대한 이야기를 나눌 기회가 있었는데, ‘이전 프로젝트에서 다뤘었고 암호에 랜덤한 값을 추가한다’라는 이야기만 할 수 있었다.
다시 볼 때가 되었구나 싶어 찾아보게 되었고, 잘 정리된 글이 있어서 보면서 다시 리마인드 했다.
보통 비밀번호를 저장할 때 SHA-256 같은 단방향 해시함수를 통해 나온 결과를 저장한다. 이 때 이 결과를 다이제스트(digest)라고 한다.
단방향 해시함수는 복호화가 불가능하기 때문에 추후 인증 과정에 들어온 값의 다이제스트과 저장한 다이제스트를 비교하여 인증 성공여부를 결정한다.
그러면 이것만으로도 안전한 것 아닐까? 해시 값은 유출되더라도 복호화가 되지 않으니?라고 할 수 있지만, 실상은 그렇지 않다고 한다.
왜냐하면 많이 사용되는 단방향 알고리즘에 대해서 다양한 문자열 비밀번호들에 대한 다이제스트를 모아놓는 ‘레인보우 테이블’들이 존재하고, 이를 활용해 비밀번호를 유추해볼 수 있기 때문이다.
또한 이 뿐만 아니라 브루트포스 방식을 통해 비밀번호를 맞춰보려고 하는데, 단순한 해시함수를 사용한다면 적은 시간 내 더 많은 해시함수를 돌려서 비밀번호를 유추해볼 수 있으므로 해커에게 좋은 상황이 될 수 있다.
그러면 이러한 문제를 해결하기 위해 어떠한 방법을 사용할까?
글에서는 2가지 방법이 소개되었는데 Key stretching과 Salt이다. 또한, 이 둘을 혼합해 활용할 수도 있다.
Key Stretching은 단방향 해시함수를 단 한 번 실행하는 것이 아니라 N번 수행하는 것이다.
해시함수를 사용한 결과물에 대해 다시 해시함수를 적용하면서 기존 Plain 비밀번호를 더 숨키고자 하는 것이다.
이를 사용하면 위에서 언급했던 레인보우 테이블에서 비밀번호를 유추하기 어려워지고, 해커 입장에서 브루트포스를 하는데 더 많은 연산이 들어가게 되어 많은 시간이 걸리게 만들 수 있다.
하지만 레인보우 테이블에서도 특정 다이제스트에 대해 몇 번 해시함수를 수행하였는가까지 기록하고 있는 경우가 많다고 한다. 즉, N 번 실행하였어도 그 결과에 대한 원문을 유추해볼 수 있는 것이다.
그리고 추가적인 문제가 있는데, 여러 사이트들이 다 같은 단방향 해시함수를 사용하고 있는 상황에서 유저가 여러 사이트에 대해 다 같은 비밀번호를 사용하고 있을 경우, 한 사이트에서 비밀번호가 유출되버리면 모든 사이트에 대해서도 유출된 것과 마찬가지가 되어버린다.
이런 문제를 막기 위해 등장한 것이 Salt이다. 비밀번호에 특정 무작위한 문자열을 더해 기존 비밀번호에 복잡성/무작위성을 더하는 것이다 (음식에 소금치듯 말이다). Salt를 더한 비밀번호를 해시함수를 통해 암호화해서 저장하게 된다.
특정 유저에 대해 Salt를 생성해 활용하는 과정에서 유저의 정보에 Salt도 저장해야만 한다. 추후 비밀번호 인증 시에도 Salt를 더해 인증해야하기 때문이다.
결국, 이러한 Salt는 운영되는 사이트마다 다를 수 밖에 없고 한 사이트에서 다이제스트가 유출되어도 다른 사이트에서는 다 다르게 구성되어서 유추하기 더 어려워질 것이다. 또한 레인보우 테이블에서 원본 값이 찾아졌어도 Salt가 더해져있는 값이기에 Salt까지 알아내지 않는 한 비밀번호 원문을 유추하기 어려워진다.
근데 당연히 Salt도 단순하게 만들거나 짧게 만들면 그렇게 효과적이지 못하다. 위 링크 글의 Generating a Good Random Salt을 참조하자.
위에서 언급한 Key stretching 방식과 Salt 방식을 혼합해 활용하면 더 안전한 방식의 암호화가 가능해진다.
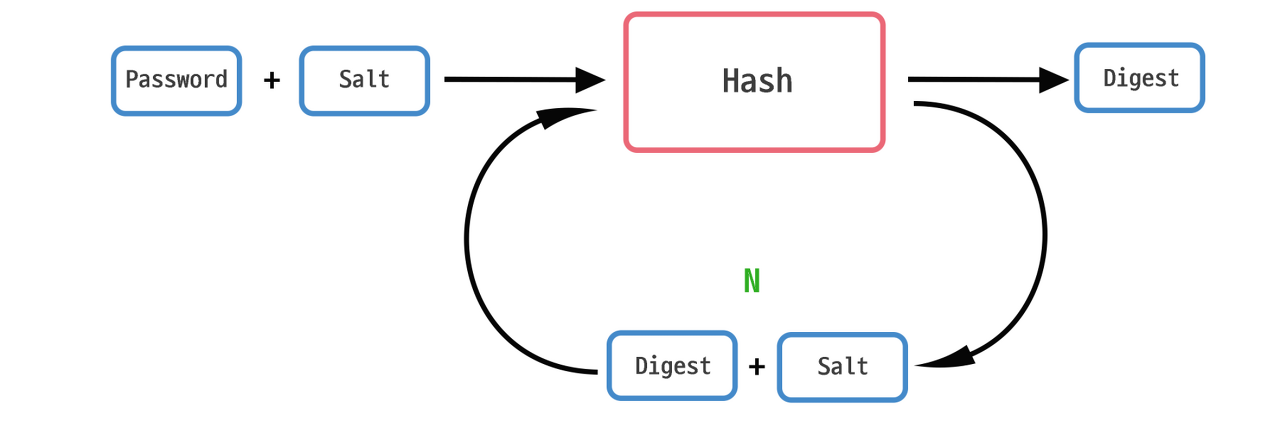
근데 사실 위 링크 글에서는 이러한 과정을 직접 개발하는 것은 잘못 이해한 것을 바탕으로 만들어 질 수 있어서 오히려 위험이 될 수 있다고 이야기한다 (보안업체에서 작성한 글인 것을 감안할 것). 그러므로 원리를 이해하고 이미 잘 구현되어 있는 구현체들을 활용하는 편이 좋을 수도 있다는 생각이 들었다.
A misstep in your home-made security strategy may lead to extensive damage to your business, users, and reputation.